Ridge and Lasso in Python
For many machine learning problems with a large number of features or a low number of observations, a linear model tends to overfit and variable selection is tricky. Models that use

In this tutorial, we will examine Ridge and Lasso regressions, compare it to the classical linear regression and apply it to a dataset in Python. Ridge and Lasso build on the linear model, but their fundamental peculiarity is regularization. The goal of these methods is to improve the loss function so that it depends not only on the sum of the squared differences but also on the regression coefficients.
The main difference between Ridge regression and Lasso is how they assign a penalty term to the coefficients. We will explore this with our example, so let's start.
We will work with the Diamonds dataset, which is freely available online: http://vincentarelbundock.github.io/Rdatasets/datasets.html. It contains the prices and other attributes of almost 54,000 diamonds. We will be predicting the price using the available attributes and compare the results for Ridge, Lasso, and OLS.
# Import libraries
import numpy as np
import pandas as pd
# Upload the dataset
diamonds = pd.read_csv('diamonds.csv')
diamonds.head()
# Drop the index
diamonds = diamonds.drop(['Unnamed: 0'], axis=1)
diamonds.head()
# Print unique values of text features
print(diamonds.cut.unique())
print(diamonds.clarity.unique())
print(diamonds.color.unique())
As you can see, there are a finite number of variables, so we can transform these categorical variables
# Import label encoder
from sklearn.preprocessing import LabelEncoder
categorical_features = ['cut', 'color', 'clarity']
le = LabelEncoder()
# Convert the variables to numerical
for i in range(3):
new = le.fit_transform(diamonds[categorical_features[i]])
diamonds[categorical_features[i]] = new
diamonds.head()
Before building the models, let's first scale data. Lasso and Ridge put constraints on the size of the coefficients associated
# Import StandardScaler
from sklearn.preprocessing import StandardScaler
# Create features and target matrixes
X = diamonds[['carat', 'depth', 'table', 'x', 'y', 'z', 'clarity', 'cut', 'color']]
y = diamonds[['price']]
# Scale data
scaler = StandardScaler()
scaler.fit(X)
X = scaler.transform(X)
Now, we can basically build the Lasso and Ridge models. But for now, we will train it on the whole dataset and look at an R-squared score and on the model coefficients. Note, that we are not setting the alpha, it is defined as 1.
# Import linear models
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
# Create lasso and ridge objects
lasso = linear_model.Lasso()
ridge = linear_model.Ridge()
# Fit the models
lasso.fit(X, y)
ridge.fit(X, y)
# Print scores, MSE, and coefficients
print("lasso score:", lasso.score(X, y))
print("ridge score:",ridge.score(X, y))
print("lasso MSE:", mean_squared_error(y, lasso.predict(X)))
print("ridge MSE:", mean_squared_error(y, ridge.predict(X)))
print("lasso coef:", lasso.coef_)
print("ridge coef:", ridge.coef_)
These two models give very similar results. So, we will split the data into training and test sets, build Ridge and Lasso, and choose the regularization parameter with the help of GridSearch. For that, we have to define the set of parameters for GridSearch. In this case, the models with the highest R-squared score will give us the best parameters.
# Make necessary imports, split data into training and test sets, and choose a set of parameters
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings("ignore")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=101)
parameters = {'alpha': np.concatenate((np.arange(0.1,2,0.1), np.arange(2, 5, 0.5), np.arange(5, 25, 1)))}
linear = linear_model.LinearRegression()
lasso = linear_model.Lasso()
ridge = linear_model.Ridge()
gridlasso = GridSearchCV(lasso, parameters, scoring ='r2')
gridridge = GridSearchCV(ridge, parameters, scoring ='r2')
# Fit models and print the best parameters, R-squared scores, MSE, and coefficients
gridlasso.fit(X_train, y_train)
gridridge.fit(X_train, y_train)
linear.fit(X_train, y_train)
print("ridge best parameters:", gridridge.best_params_)
print("lasso best parameters:", gridlasso.best_params_)
print("ridge score:", gridridge.score(X_test, y_test))
print("lasso score:", gridlasso.score(X_test, y_test))
print("linear score:", linear.score(X_test, y_test))
print("ridge MSE:", mean_squared_error(y_test, gridridge.predict(X_test)))
print("lasso MSE:", mean_squared_error(y_test, gridlasso.predict(X_test)))
print("linear MSE:", mean_squared_error(y_test, linear.predict(X_test)))
print("ridge best estimator coef:", gridridge.best_estimator_.coef_)
print("lasso best estimator coef:", gridlasso.best_estimator_.coef_)
print("linear coef:", linear.coef_)
Our score raises a little, but with these values of alpha, there is only a small difference. Let's build coefficient plots to see how the value of alpha influences the coefficients of both models.
# Import library for visualization
import matplotlib.pyplot as plt
coefsLasso = []
coefsRidge = []
# Build Ridge and Lasso for 200 values of alpha and write the coefficients into array
alphasLasso = np.arange (0, 20, 0.1)
alphasRidge = np.arange (0, 200, 1)
for i in range(200):
lasso = linear_model.Lasso(alpha=alphasLasso[i])
lasso.fit(X_train, y_train)
coefsLasso.append(lasso.coef_)
ridge = linear_model.Ridge(alpha=alphasRidge[i])
ridge.fit(X_train, y_train)
coefsRidge.append(ridge.coef_[0])
# Build Lasso and Ridge coefficient plots
plt.figure(figsize = (16,7))
plt.subplot(121)
plt.plot(alphasLasso, coefsLasso)
plt.title('Lasso coefficients')
plt.xlabel('alpha')
plt.ylabel('coefs')
plt.subplot(122)
plt.plot(alphasRidge, coefsRidge)
plt.title('Ridge coefficients')
plt.xlabel('alpha')
plt.ylabel('coefs')
plt.show()
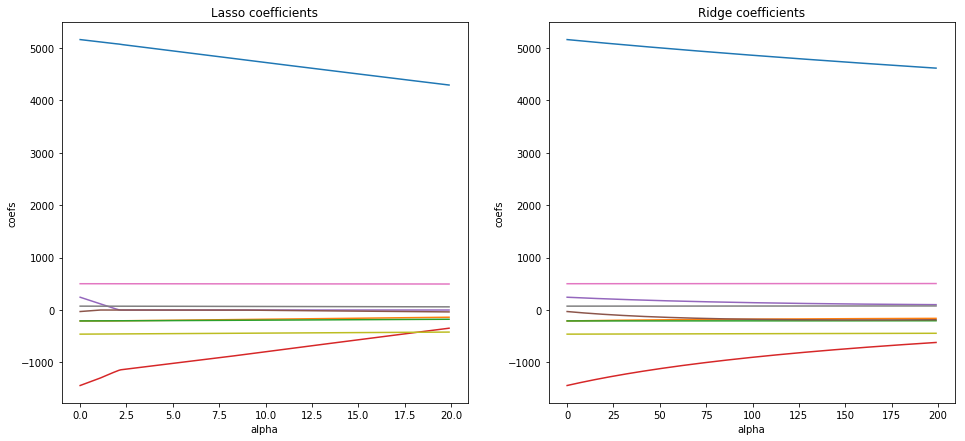
As a result, you can see that when we raise the alpha in Ridge regression, the magnitude of the coefficients decreases, but never attains zero. The same scenario in Lasso influences less on the large coefficients, but the small ones Lasso reduces to zeroes. Therefore Lasso can also be used to determine which features are important to us and keeps the features that may influence the target variable, while Ridge regression gives uniform penalties to all the features and in such way reduces the model complexity and prevents multicollinearity.
Now, it’s your turn!